AWS S3 Object Finder | Boto3 Script

Hi there, I'm a prior hybrid network engineer transformed cloud engineer, and I enjoy writing posts about my technical journey including implementation guides, insights, tips, scripts and graphics from what I've gleaned along the way.
Overview
🔎 Quickly find AWS S3 Objects inside buckets hosting huge volumes of files using my latest Boto3 script! You can easily locate specific objects in your AWS profile by providing a few command line arguments. By specifying the AWS profile, bucket name, object name, and optional prefix you can efficiently search for objects and obtain a list of matching keys, allowing you to pinpoint the location of a particular file.
This 📜 performs the following tasks:
✔️ Handle pagination when dealing with large buckets containing thousands of objects
✔️ Perform a recursive search for an object in an S3 bucket, considering the object's name and optional prefix
✔️ Display the keys of matching objects found in the bucket
✔️ List all buckets in a specified AWS profile
✔️ List top-level prefixes in a specified bucket
Purpose
This AWS S3 Object Finder script is particularly helpful when troubleshooting upload error logs especially when dealing with buckets that host thousands of objects and extensive prefixes. In these scenarios, manually searching for objects can be very time-consuming. By utilizing the script's pagination and object prefix features, you can significantly speed up the search process and narrow down the results to the desired subset of objects. This saves both time and effort allowing you to efficiently troubleshoot specific object data without having to search for objects manually.
Script Functionality
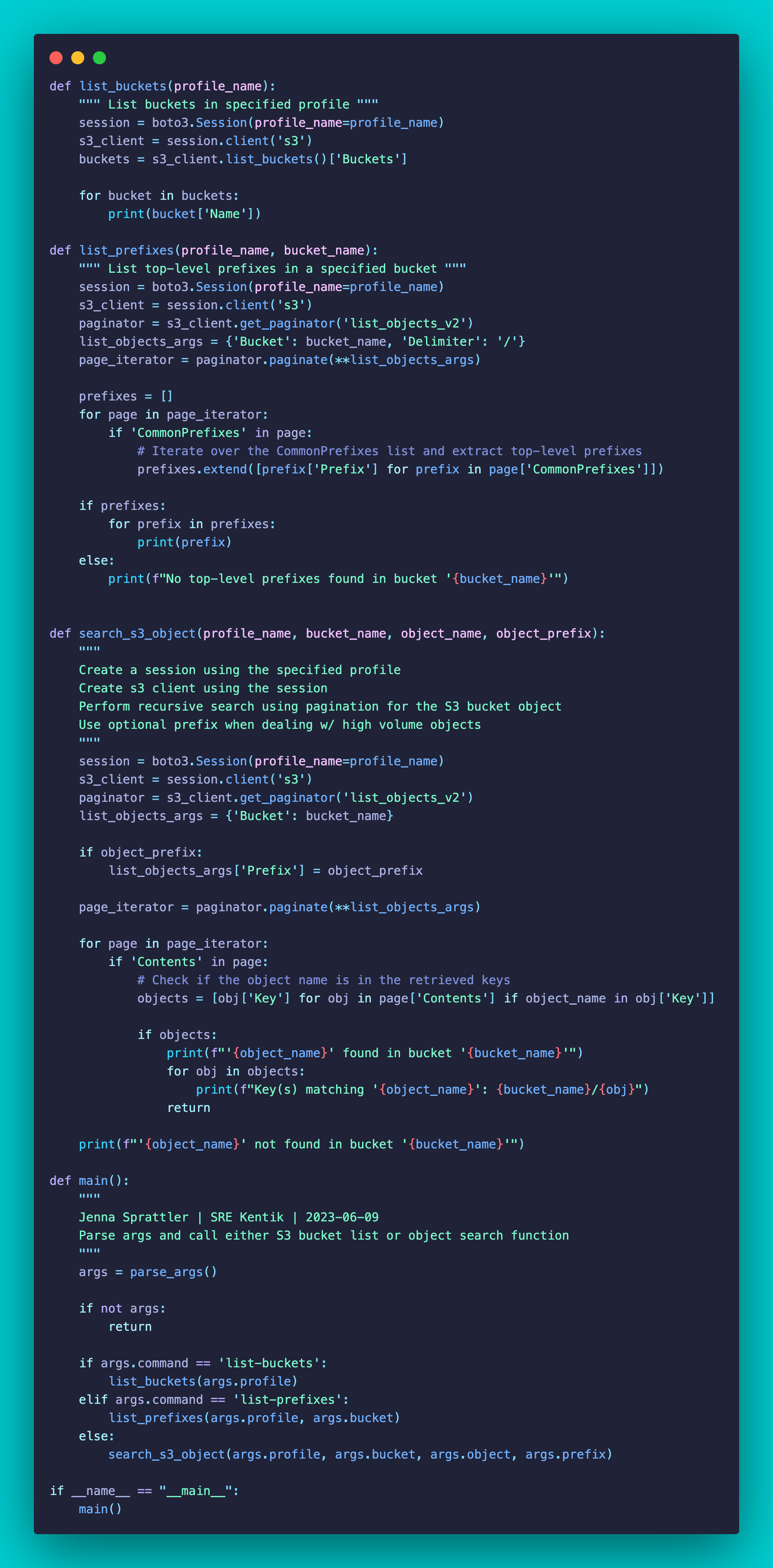
Link to the script: https://github.com/jksprattler/aws-tools/blob/main/scripts/aws_s3_object_finder.py
Usage
Here's a look at the options available from the -h/--help output:
❯ python aws_s3_object_finder.py --help
usage: aws_s3_object_finder.py [-h] -p PROFILE [-b BUCKET] [-o OBJECT] [-x PREFIX] {list-buckets,list-prefixes} ...
Search for an object in an S3 bucket.
positional arguments:
{list-buckets,list-prefixes}
Additional commands
list-buckets List buckets in profile, use after -p
list-prefixes List top-level prefixes in bucket, use after -p and -b
optional arguments:
-h, --help show this help message and exit
-p PROFILE, --profile PROFILE
AWS profile name
-b BUCKET, --bucket BUCKET
S3 bucket name
-o OBJECT, --object OBJECT
Object name to search for
-x PREFIX, --prefix PREFIX
Object prefix for high volume bucket search
Here's an example of listing all buckets in a specified AWS profile:
❯ python aws_s3_object_finder.py -p cloud-sandbox list
sandbox-cloudtrail
sandbox-trail-bucket
lstest2022
Here's an example of listing all top-level prefixes in a specified bucket:
❯ python aws_s3_object_finder.py -p default -b jennasprattler.com list-prefixes
assets/
images/
Here's an example of listing all S3 objects in a specified bucket by calling a keyword in the prefix as the object:
❯ python aws_s3_object_finder.py -p cloud-sandbox -b sandbox-cloudtrail -o us-west-2
'us-west-2' found in bucket 'sandbox-cloudtrail'
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_HzrxfJgKaRrQr2d3.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_Uyg59kXzzIB0y2YS.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_rzKX1qISHRXL6aru.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2105Z_GlZuUn6pUrCDzbhr.json.gz
### Redacted for brevity
Here's an example of listing all objects in a bucket under a specific prefix where there are 1,000s of objects requiring pagination. If you don't know the specific file/object name then you can define the closest matching prefix anywhere in the key as the object argument followed by the initial prefix of the key as the prefix argument:
❯ python aws_s3_object_finder.py -p cloud-sandbox -b sandbox-cloudtrail -o us-west-2 -x AWSLogs/
'us-west-2' found in bucket 'sandbox-cloudtrail'
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_HzrxfJgKaRrQr2d3.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_Uyg59kXzzIB0y2YS.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_rzKX1qISHRXL6aru.json.gz
### Redacted for brevity
In some cases, you will need to be more granular with how you specify objects and prefixes based on your prefix structure. In other words, you could have duplicate or overlapping prefix names causing a search to fail. The solution for this is to specify additional values in your delimiter-separated values for '/' for the prefix argument:
❯ python aws_s3_object_finder.py -p cloud-sandbox -b sandbox-cloudtrail -o us-west-2 -x AWSLogs/accountId/CloudTrail/
'us-west-2' found in bucket 'sandbox-cloudtrail'
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_HzrxfJgKaRrQr2d3.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_Uyg59kXzzIB0y2YS.json.gz
Key(s) matching 'us-west-2': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_rzKX1qISHRXL6aru.json.gz
### Redacted for brevity
Here's an example of finding a specific object/filename in a bucket hosting thousands of objects by specifying a prefix with the object argument:
❯ python aws_s3_object_finder.py -p cloud-sandbox -b sandbox-cloudtrail -o accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz -x AWSLogs/
'accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz' found in bucket 'sandbox-cloudtrail'
Key(s) matching 'accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz': sandbox-cloudtrail/AWSLogs/accountId/CloudTrail/us-west-2/2022/01/20/accountId_CloudTrail_us-west-2_20220120T2100Z_1bxLMBY0uRL1X67x.json.gz
Code Explanation
Inside the main function, the args are set to the parse_args() function. If no arguments are provided the script outputs the usage from the parser and exits. The next conditional will run the list_buckets function if the list-buckets argument is provided with a profile. Next, it will run the list_prefixes function if the list-prefixes argument is provided with a profile and bucket. Finally, the search_s3_object function is run when at least the profile, bucket and object are provided - the prefix is optional.
def main():
""" Parse args and call either S3 bucket list or object search function """
args = parse_args()
if not args:
return
if args.command == 'list-buckets':
list_buckets(args.profile)
elif args.command == 'list-prefixes':
list_prefixes(args.profile, args.bucket)
else:
search_s3_object(args.profile, args.bucket, args.object, args.prefix)
if __name__ == "__main__":
main()
Below is the parse_arguments() function. This is self-explanatory by reviewing the help comments for each of the arguments. Also, see usage in the output example above.
def parse_args():
""" Define cli args to be parsed into main() """
parser = argparse.ArgumentParser(description='Search for an object in an S3 bucket.')
parser.add_argument('-p', '--profile', required=True, help='AWS profile name')
parser.add_argument('-b', '--bucket', help='S3 bucket name')
parser.add_argument('-o', '--object', help='Object name to search for')
parser.add_argument('-x', '--prefix', help='Object prefix for high volume bucket search')
subparser = parser.add_subparsers(dest='command', help='Additional commands')
subparser.add_parser('list-buckets',
help='List buckets in profile, use after -p')
subparser.add_parser('list-prefixes', help='List top-level prefixes in bucket,\
use after -p and -b')
args = parser.parse_args()
if args.command == 'list-buckets':
return args
if args.command == 'list-prefixes' and args.bucket:
return args
if not args.bucket or (not args.bucket and not args.command == 'list-prefixes') \
or not args.object:
parser.print_usage()
return None
return args
If the user provides the list-buckets argument then the list_buckets(profile_name) function is called and provides the output of all buckets in the specified AWS profile. It creates a session using the provided profile name, establishes an S3 client using the session, and sends a request to list the buckets associated with the profile.
def list_buckets(profile_name):
""" List buckets in specified profile """
session = boto3.Session(profile_name=profile_name)
s3_client = session.client('s3')
buckets = s3_client.list_buckets()['Buckets']
for bucket in buckets:
print(bucket['Name'])
If the user provides the list-prefixes argument then the list_prefixes(profile_name, bucket_name) function is called and provides the output of all top-level prefixes within the specified bucket.
def list_prefixes(profile_name, bucket_name):
""" List top-level prefixes in a specified bucket """
session = boto3.Session(profile_name=profile_name)
s3_client = session.client('s3')
paginator = s3_client.get_paginator('list_objects_v2')
list_objects_args = {'Bucket': bucket_name, 'Delimiter': '/'}
page_iterator = paginator.paginate(**list_objects_args)
prefixes = []
for page in page_iterator:
if 'CommonPrefixes' in page:
# Iterate over the CommonPrefixes list and extract top-level prefixes
prefixes.extend([prefix['Prefix'] for prefix in page['CommonPrefixes']])
if prefixes:
for prefix in prefixes:
print(prefix)
else:
print(f"No top-level prefixes found in bucket '{bucket_name}'")
Excluding any of the "list*" arguments, when the user provides the --object and/or --prefix argument with the AWS profile then the search_s3_object(profile_name, bucket_name, object_name, object_prefix) function is called. It creates a session using the specified profile name, creates an S3 client using the session, and sends a request to list the objects in the specified bucket. The response is then processed, filtering the objects based on the provided object name and object prefix. If any matching objects are found, their keys are printed to the console, indicating their location within the bucket. If no matching objects are found, a message is printed to indicate that the object was not found in the bucket.
def search_s3_object(profile_name, bucket_name, object_name, object_prefix):
"""
Create a session using the specified profile
Create s3 client using the session
Perform recursive search using pagination for the S3 bucket object
Use optional prefix when dealing w/ high volume objects
"""
session = boto3.Session(profile_name=profile_name)
s3_client = session.client('s3')
paginator = s3_client.get_paginator('list_objects_v2')
list_objects_args = {'Bucket': bucket_name}
if object_prefix:
list_objects_ars['Prefix'] = object_prefix
page_iterator = paginator.paginate(**list_objects_args)
for page in page_iterator:
if 'Contents' in page:
# Check if the object name is in the retrieved keys
objects = [obj['Key'] for obj in page['Contents'] if object_name in obj['Key']]
if objects:
print(f"'{object_name}' found in bucket '{bucket_name}'")
for obj in objects:
print(f"Key(s) matching '{object_name}': {bucket_name}/{obj}")
return
print(f"'{object_name}' not found in bucket '{bucket_name}'")
A few items to highlight from the search_s3_object() function:
list_objects_args = {'Bucket': bucket_name}: This line creates a dictionary calledlist_objects_argswith a key-value pair. The key is'Bucket', and the value is thebucket_namevariable. This dictionary is used to specify the bucket name when calling thelist_objects_v2API.if object_prefix: list_objects_args['Prefix'] = object_prefix: This conditional statement checks if theobject_prefixvariable has a value. Ifobject_prefixis not empty orNone, it means a prefix was provided. In that case, it adds another key-value pair to thelist_objects_argsdictionary. The key is'Prefix', and the value is theobject_prefixvariable. This prefix specifies a filter to narrow down the objects returned by the API call.page_iterator = paginator.paginate(**list_objects_args): This line creates apage_iteratorobject using thepaginator.paginate()method. The double asterisks**beforelist_objects_argsunpacks the dictionary into keyword arguments. This means that thepaginator.paginate()method receives the dictionary key-value pairs as separate arguments. In this case, it passes the'Bucket'and'Prefix'arguments to thepaginator.paginate()method.These provide the necessary arguments for the
paginator.paginate()method based on the provided bucket name and optional object prefix. It allows you to paginate through the S3 bucket objects, retrieving a subset of objects at a time, based on the provided arguments while still offering flexibility in that the--prefixargument is not required to run the script although it will still be needed if your bucket consists of thousands of objects.
Conclusion
This approach to searching for S3 bucket objects provides quick troubleshooting capability and enables you to locate data with ease. Whether you need to identify a precise object location or navigate through large buckets with complex prefixes, this AWS Object Finder script can be a helpful tool when working with AWS S3!
Boto3 Resources
list_objects_v2 - Boto3 1.26.151 documentation: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3/client/list_objects_v2.html
list_buckets - Boto3 1.26.151 documentation: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3/client/list_buckets.html
Paginators - Boto3 1.26.151 documentation: https://boto3.amazonaws.com/v1/documentation/api/latest/guide/paginators.html



